01:00
Overfitting
STAT 20: Introduction to Probability and Statistics
Agenda
- Announcements
- Reading Questions
- Break
- Worksheet
- Break
- Lab: Part 2
- Appendix
Announcements
- Portfolio 7 (five worksheets) due Monday at 5pm.
- Final is next Thursday, in-class. A two sided, handwritten cheatsheet is allowed.
- Quiz 3 grades will be out early next week.
Reading Questions
- Please put your laptops under your desk and your phones away.
- Write your name, ID, and bubble in Version “A” on your answer sheet.
- You may work only with those at your table!
I have a data frame with 100 observations and 10 variables. Using an 80/20 train/test set split, what will be the dimensions (rows x columns) of my training data frame?
- A: 80 * 100
- B: 80 * 10
- C: 10 * 80
- D: 100 * 80
- E: The correct answer is not here.
00:40
How should the data frame be split, assuming the 80/20 split?
A: The first 80 rows of the data are assigned to training; the last 20 are assigned to testing.
B: The first 20 rows of the data are assigned to training; the last 80 are assigned to testing.
C: Sample 100 rows from the table with replacement. The first 80 rows are assigned to training; the last 20 are assigned to testing.
D. Sample 100 rows from the table without replacement. The first 80 rows are assigned to training; the last 20 are assigned to testing.
00:45
Which of the following are examples of overfitting? Select all that apply.
A: A student fails a final exam because they did not go over the practice final exam, which would have given them practice with important concepts.
B: A student fails a final exam because they memorized the answers to the practice final exam without understanding the important concepts.
C: Fitting a model that crosses through all points in the training set.
D: Fitting a model function that more or less follows the points in the training set.
E: A student fails a final exam in spite of healthy studying habits because the professor gives out an exam containing topics which were not taught in the course.
01:00
Suppose I fit a model with a high amount of overfitting. Which of the following scenarios is most likely?
- A: Training \(R^2\) is high, testing \(R^2\) is lower.
- B: Training and testing \(R^2\) are both high.
- C: Testing \(R^2\) is high, training \(R^2\) is lower.
- D: Training and testing \(R^2\) are both low.
00:30
True or False: A lower degree polynomial model is more likely to overfit than a higher degree polynomial model.
A: True
B: False
00:30
Break
05:00
Worksheet: Overfitting
35:00
Break
05:00
Lab: Part 2
35:00
Appendix
Concept Questions
Overfitting or not? (Taken from the reading questions)
Which one of these (open pollev.com) is not an example of overfitting (either in real life or in statistics)?
Are RSS and R square related?
01:00
If I decrease the RSS (e.g. by fitting a more accurate model) does the \(R^2\) value necessarily increase?
Overfit models
00:30
Fill in the blanks: overfit models tend to
fit the training data (well/poorly)
fit the testing data (well/poorly)
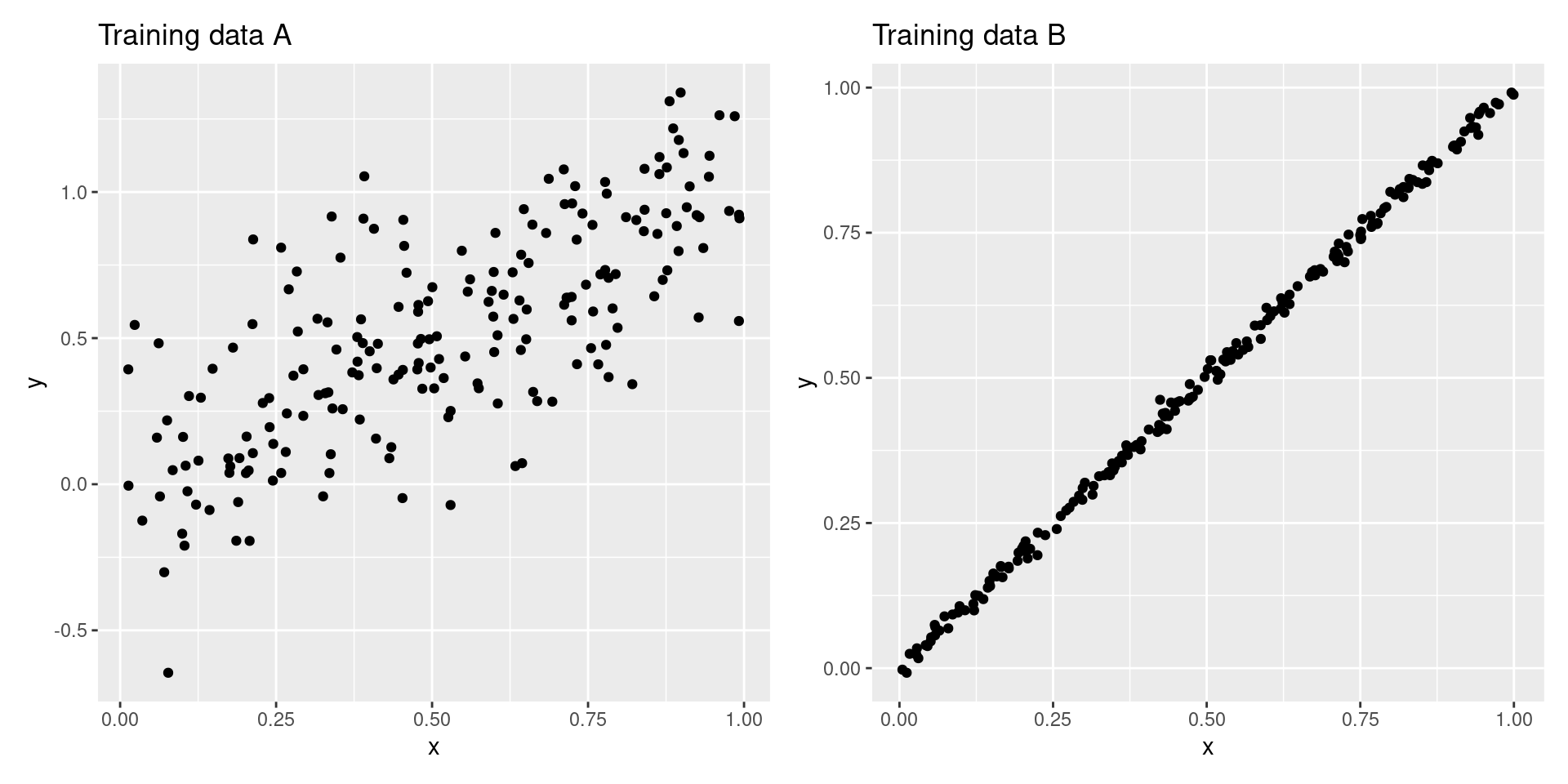
Where is overfitting worse?
01:00
Suppose I overfit my model to the training data. In which scenario (for which training data) would I expect the test set performance to be significantly worse? Assume that the testing sets A and B look like their corresponding training sets.